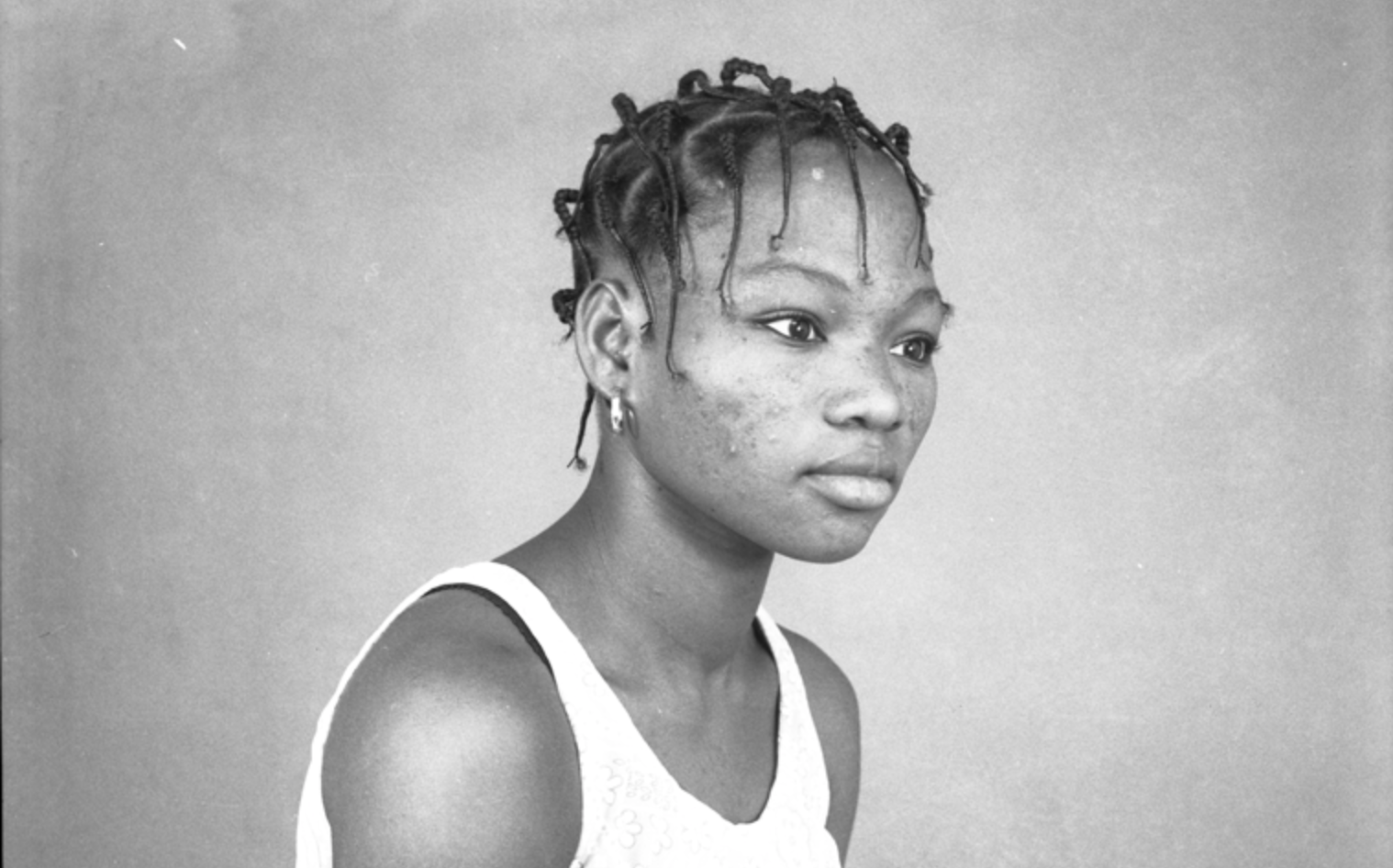Large-scale pretrained models, or foundation models, have demonstrated unprecedentedly
strong performance on various tasks but they also have a large number of parameters. Low-Rank Adaptation
(LoRA) is extensively utilized in text-to-image models for the accurate rendition of specific elements
like distinct characters or unique styles in generated images. Low-Rank Adaptation (LoRA) stands out for
its ability to fine-tune image synthesis with remarkable precision and minimal computational load. LoRA
excels by specializing in one element — such as a specific character, a particular clothing, a unique
style, or other distinct visual aspects — and being trained to produce diverse and accurate renditions
of this element in generated images. Low-Rank Adaptation of Large Language Models (LoRA) is used to
address the challenges of fine-tuning large language models (LLMs). Models like GPT and Llama, which
boast billions of parameters, are typically cost-prohibitive to fine-tune for specific tasks or domains.
LoRA preserves pre-trained model weights and incorporates trainable layers within each model block. This
results in a significant reduction in the number of parameters that need to be fine-tuned and
considerably reduces GPU memory requirements.
IS FINE-TUNING NECESSARY?
Before diving into the technical aspects, let's begin by analyzing your text prompts with these critical
questions
(alternatively, use our critique
worksheet):
Are visual elements rooted in oral traditions described in the text
prompt?
If yes, are these elements unvisualized in the generated image?
Are visual elements based on undigitized perspectives and histories
described in the text prompt? If yes, are these elements unvisualized in the generated image?
Are visual elements from low-resource domains described in the text
prompt? If yes, are these elements unvisualized in the generated image?
Are spurious correlations visualized in the generated image?
Are toxic and ethically questionable attributes visualized in the
generated image?
Despite the advanced capabilities of text-to-image models, they often face a well-documented challenge:
misalignment between text prompts and generated images. Misalignment makes models unreliable
and prone to hallucinating expected visual representations. Research has shown that misalignment occurs
because text-to-image models are statistical tools that replicate patterns observed in their vast, uncurated
training datasets. These datasets are far
from neutral; they are embedded
with assumptions
and biases shaped by institutional frameworks, resource distributions, and historical patterns.
They overrepresent the views, values, and modes of
communication of dominant voices, while
simultaneously mis/underrepresenting minoritized perspectives. Therefore, datasets are partial representation of the world,
and text-to-image algorithms trained on such corpora reflect this partiality which leads to inconsistent performance
across different sociodemographic groups. It's important to note that the dimensions along which misalignment occurs can also be
rooted in culture-specific or localized social hierarchies.
In scenarios where generated images fail to align with your artistic vision, you may consider
abandoning image generation in favor
of alternative visual processing methods. However, if you decide to proceed with image generation,
we recommend finetuning the foundation model for improved performance.
Fine-tuning is the process of adapting a
pre-trained
text-to-image model to effectively generate
specialized images based on relatively small amounts of relevant, in-domain data.
By providing the model with supplementary samples, it learns additional parameters that help encode
concepts and content relevant to your artistic goals.
CURATE A DATASET
The fine-tuning process requires two critical components: a high-quality visual dataset and domain
expertise.
A visual dataset can range from personal family
photographs, as used by artist Aarati Aakapedi in the project A.KIN, to themed collections like
Fabiola
Larios's taco
dataset or Linda Dounia's endangered West
African plants. For optimal performance, your dataset should consist of high-fidelity samples that
closely resemble your intended artistic output.
First,
begin by defining the objectives of your dataset. Did you answer 'YES' to any of the prompt critique
questions? Identify the exact elements that were unvisualized.
Determine the composition of your data. Where will you source images that fill in the gaps?
To avoid overfitting—where the model becomes too narrowly attuned to your specific dataset—ensure
that the images are diverse and not too similar to each other.
To kickstart your finetuning process, below we provide a K-12 friendly data library. The datasets are research-permissive, and licensed under Creative
Commons Zero (CC0) for unrestricted use, or permitted for non-commercial and educational
fair
use, in compliance with The United States copyright law. Each dataset contains 100 images, provided in a zipped folder. Images are
in jpg/png
format, with a minimum resolution of 700px (W x H). To download a dataset,
click the download icon download
We recommend using Low-Rank Adaptation (LoRA) fine-tuning tools for your projects. LoRA fine-tuning
is an efficient method that requires no more than 20 images of the data subject to achieve effective
results. This method is particularly suitable for art educational settings, as it simplifies the fine-tuning
process and reduces the need for extensive datasets.
For detailed guidance, please refer to our lesson plan on LGBTQI perspectives.
This dataset presents a collection of medieval paintings and sculptures depicting Black/Brown skinned
Virgin
Mary and child. It includes
original works and reproductions for churches, altars and other sacred items.
Collection of 90's Hip Hop party and event flyers, designed for events in the Bronx, New York. These
flyers
provide a rich snapshot of the era, detailing early Hip Hop groups, MCs, DJs, promoters, venues, dress
codes, admission prices, shout outs, and more.
Cornrows, box braids, and threaded hairstyles from Mali, captured during the twentieth century.
Photographers: Mamadou Cissé, Adama Kouyaté, Abdourahmane
Sakaly, Malick Sidibé, Tijani Sitou.
Tables designed by manufacturing companies in the United states between the 1800 and 1900s: Pottier and
Stymus Manufacturing Company, Herter Brothers, United Society of Believers in Christ’s Second Appearing
(“Shakers”),Charles-Honoré Lannuier.
This collection showcases vinyl sleeves of Ghanian highlife music from the 1950's, 1960's and the
1970's.
The covers include artworks by: Guy Hayford Agameti, Ebo Prah, M. Bampoe, Ebele & Chynie, Meridian Art
Services, Osansa, E.E. Lamptey, Mantsefio Bampoe, Fred Attoh, G. Annan-Forson, Willis E. Bell, K.
Setordji &
K. Frimpong, Augustus Taylor, Samuel Buabin, & more.